The purpose of this paper is to show how empirical data collected in household surveys can be transformed into indices of social capital and its outcome. Nonlinear Principal Component Analysis (NLPCA) transformed the original data into dimensions of SC. The first four dimensions explained more than 70% of the variance and were related to social networking, socialization and trust, social norms and reliance on neighbors in case of need. The NLPCA and the Cluster Analysis (CA) were than applied to the outcome variables to divide the households into one better off and one worst off group. The variables related to political commitment/participation, tension and violence were transformed into outcome dimensions through NLPCA. The CA was applied to such dimensions to cluster the households into one better off and one worst off group. Logistic regression showed that the probability of belonging to the better off group increased with the score of the households’ SC dimensions. The analytical approach described in this paper could be used to improve the measurement of SC to test hypotheeis on the determinants and the effects of SC.
Social Capital (SC) is an innovative concept but it remains difficult to quantify. SC has been the subject of intense debate during the last decade and it has been described in several ways. According to Portes (1998), individuals gain resources in terms of information and support from belonging to social networks. These resources are categorized under SC to differentiate them from the physical capital (i.e. tools) and the human capital (i.e. education). Putnam (1993) extends the concept of SC to include all types of social interactions, from the social contacts with neighbors to the participation into formal and informal organizations. The membership to clubs and associations would facilitate people cooperation, exchange of information and building of trust. A high level of SC would have beneficial effects in terms of the socioeconomic development of individuals, households, communities and countries. A low level of SC would have negative effects on the social fabric, which would be reflected in high levels of crime, ill health, unemployment and other social problems.
As described by Narayan and Pritchet (2000), the literature has dealt with SC at the micro level (individual/household/neoghbourhood), the meso level (institutions) and the macrolevel (region/country). SC can be seen as a ‘social glue’ bonding the individuals, the households, the neighborhoods, the formal and informal groups and the community as a whole. The identification with these groups and with the values they represent leads to the respect of norms and social contracts, and to the building of a sense of trust and safety. This environment at the micro level influences the efficiency of the institutional level (meso level), which reflects the values and norms existing at the micro level. This is a two-way interaction because the efficiency of the institutions influences and strengthens the SC originating from the micro level. Finally, the efficiency of the institutions is critical to the socioeconomic development at the macro level.
Several studies have focused on the above-mentioned levels and have produced different measures of SC. The study of Putnam (1993) on the variability of the institutional efficiency existing in the different regions of Italy is an example of a study, which has focused on the meso level. In his study, Putnam defines SC as similar to the ‘ notions of physical and human capital, the term social capital refers to features of social organization -- such as networks, norms, and trust that increase a society's productive potential....’. The variation in efficiency of the regional governments across Italy was interpreted as the result of the social, economic cultural and political context existing in each region. This context, which has taken centuries to develop and which has been influenced by historical events, consists of cultural values, norms, traditions and the networks of civic engagement. These elements have produced the variation in the efficiency of governments and the different levels of socioeconomic development existing across the Italian regions.
Most of the studies on SC have been conducted at the micro level through household surveys measuring the level of social interaction, density and type of membership to social networks and the sense of trust. Krishna and Uphoff (1999) analyzed several variables collected in a study of a watershed development project in India and they used factor analysis to transform the density of voluntary organizations and the sense of trust into a SC index, which was positively correlated with an index of ‘development orientated collective action’. Whiteley (2000) used the data from the World Value Survey, which has been conducted in 43 countries, to produce a SC index based on trust variables. This index, which was built through principal component analysys, was found positively associated with macroeconomic indicators. Brehm and Rahn (1997) used the factor analysis on the data from the General Social Survey, which is a series of household surveys carried out in the United States, to build a model of SC based on the interaction between civic engagement, trust and confidence in government. Grootaert (1999) analysed the data collected in a household survey in Indonesia to build an index of SC based on membership and internal heterogeneity of associations, attendance and active participation, and membership payment. This index was positively associated with households’ socioeconomic conditions measured through expenditures and access to services. In Tanzania, Narayan and Pritchett (1997) produced a measure of SC by combining households’ membership to networks and the sense of trust, and they examined the link between SC and village-level economic indicators.
Memberships to networks and trust have been considered the driving force generating SC and have been the most used measures of SC. This should not come as a surprise, considering that in most countries and cultures, having the right contacts in the right place is the key to social and economic success. In his review of the literature of SC, Fassin (2003) has summarized the work of several authors and the hypotheses on how SC would be created through the individual interactions allowed by the social structures they belong to. These interactions create access to information, job opportunities and other positive effects, which result in obligations, expectations and trust. These in turns produce respect for norms, civic and social responsibility, initiative, safety and other positive outcomes that influence institutional efficiency and socioeconomic development.
There is overall agreement among researchers that SC can be viewed into its micro, meso and macro levels, but the links between the three levels need further study. According to Brehmen and Rahn (1997) ‘SC is an aggregate concept that has its basis in individual behaviour attitude and predisposition’. These individual characteristics could be the primum movens behind the decision to join an organization and to socially interact, which will than contribute to the development of SC at the micro-level. It is likely that once SC has developed at the micro level, its effects are felt at the meso level as well.
Although, it is not known how SC at the micro level influences SC at the meso level, it is likely that this may occur through the production of ‘intermediate outcomes’ produced by the SC at the micro level. These ‘intermediate outcomes’, which are different from the final outcomes related to socioeconomic development, health and other more distant outcomes, include the sense of identity and pride, the security from crime, the political activism and participation which are the by-products of SC. These ‘intermediate outcomes’ would produce changes at the meso level, leading to higher institutional efficiency. For example, the sense of belonging to a group would lead to the sense of identity and pride, the cooperation and good relationship within the neighborhood would help to produce a sense of security, the respect for social norms would lead to the aversion towards crime and corruption, and would promote political activism. These factors that can be considered ‘intermediate outcome’ of SC would result in a pressure on the meso level to become more efficient.
The aim of this analysis is to provide a testing ground to improve the definitions and the measurements of SC and of its ‘intermediate outcomes’ at the micro-level and to measure the strength of their association. The analysis uses the variables which have been used in the literature to define SC and its outcomes. In this paper the outcome variables are those related to self confidence, participation, initiative, identity, pride, safety and trust in government. These are considered ‘intermediate outcomes’ because they are the byproduct through which SC influence more distant outcomes such as increased efficiency of the institutions and socioeconomic development. The data are from a survey carried out in Kampala, Uganda as part of the initiative promoted by the World Bank to improve the measurement of SC in developing countries (Grootaert et al. 2003). The analytical strategy is based on the use of the Non Linear Component Analysis (NLPCA) and on the Cluster Analysis (CA).
The analysis was carried out on the data collected in November 1998 in a survey of 950 households sampled in an urban area of Kampala, Uganda. The households were randomly selected from a poor urban neighbourhood of Kampala, because the objective of the survey was to test the methodology to measure Social Capital in poor urban settings of developing countries. The unit of analysis was the household and the variables that were collected to define SC included: membership in social groups, participation and contribution to the groups, heterogeneous characteristics of the members, social activities and trust (Box 1). The ‘intermediate outcomes were related to the sense of pride and identify, the political commitment and participation and the sense of security and confidence in getting help in case of need (Box 2).


The analytical strategy was to build indices of SC and intermediate outcomes and to measure their relationships. The first step was to use the NLPCA on the original variables defining SC to build dimensions or composite indices of SC. The second step was to run two logistic regression (LR) models for each outcome variable used as dependent, with the first model containing the SC dimensions as independent variables, while the second model contained the original SC variables as independent variables. The RSquares of the two models were compared to check if the goodness of fit of the dimensions was similar to that of the original SC variables in predicting individual outcomes. The third step was to use the NLPCA and the CA on the intermediate outcome variables to create dimensions of ‘intermediate outcome’ and use such dimensions to cluster the households into one better off and one worst off group. The fourth step was to use logistic regression to measure the prediction of a household to belong to the better off group given its SC dimensions.
The NLPCA was used to transform the original SC variables into a few composite indices (dimensions), which were proxies of the original variables. When variables are not linear, as it is the case with the variables defining SC, there is a need to optimally scale them by giving an optimal score that can quantify the categories of each variable. The NLPCA reveals associations across variables and optimally scales variables characterized by different units of measure by transforming them into a few dimensions with standardized metric properties.
Each dimension summarizes a proportion of the total variance of the original variables. The NLPCA estimates a non-parametric family of dimensions, where each dimension is influenced by a certain number of variables. Each variable is related to a dimension through its category quantification, which is a measure of correlation of the variable with the dimension, and through its component loading, which can be interpreted as a coefficient. A review of the NLPCA can be found in Kramer (1991).
The NLPCA was used to extract the SC dimensions from the original variables. All the original SC variables were entered into the first model and several runs were carried out in a stepwise approach to exclude non-essential variables. In each run, the variables were excluded if their component loading was less than 0.1 and if their elimination increased the goodness of the model in explaining the total variance. After applying the NLPCA each household had its own SC profile, where the original variables were optimally quantified into dimensional scores.
The first strategy was to compare the power of the SC dimensions in predicting a given intermediate outcome versus the predictive power of the original SC variables. For each intermediate outcome as dependent, there were two LR models, in the first model the dimensions were entered as independent variables; while in the second model the original SC variables were entered as independent variables. For each intermediate outcome, the RSquare of the LR model containing the dimensions was compared with the Rsquare of the LR model containing the original SC variables.
The second strategy was to categorize each household as better off and as worst off on the basis of its intermediate outcomes and to measure the probability of a household to belong to the better off group given its SC dimensions’ score. This strategy had the objective to measure the association of the SC dimensions with an overall measure of intermediate outcome. This was done by applying the NLPCA on the intermediate outcome variables to construct dimensions and by using the cluster analysis (CA) on the intermediate outcome dimensions to partition the households into two clusters, which differed in overall intermediate outcome. The algorithm k-means, according to Andemberg (1973) was employed to partition the households into two clusters, which were characterized by different intermediate outcome. Finally, a LR model was carried out to measure the power of the household’s SC dimensions (independents) in predicting the probability of belonging to the better off group (dependent).
The NLPCA carried out on the original SC variables produced four dimensions that explained more than 70% of the variance. Table 1 shows the category quantifications that are measures of correlation of the original variables with each dimension. Table 2 shows the component loadings that can be interpreted like the beta coefficient of multiple regression. A given dimension score increases if the component loading is positive and decreases if it is negative. For example the first dimension increased with the number of groups/associations, to which the household belonged because this variable had a positive component loading on the first dimension.
The first dimension explained the greatest proportion of the variance and it was characterized by variables related to social networking. As shown by the bottom of table 1, the first dimension explained 43% of the variance. It was a social network dimension because it was characterized by group membership, group participation, money contribution to the associations they belonged to, and heterogeneity of the members in terms of clan/ethnicity/religion. These variables defined only the first dimension because they were not loaded on other dimensions.
The second dimension explained 12% of the variance and was characterized by variables that were proxies of socialization, trust and relationships with neighbors. These variables included the:
The third and fourth dimensions explained a lower proportion of the variance and were less clearly defined because the variables that were loaded on them were also loaded on the second dimension. The third dimension was characterized by variables related to social norms, including expectation about people helpfulness, trustworthiness and fairness. Frequency and heterogeneity of social contacts (i.e. ethnicity/religion) was shared with the second dimension as well. Reliance on the neighborhood in case of need characterized the fourth dimension but this variable was also loaded on the second dimension.
The information from the original variables was optimally scaled into dimensions’ standardized unit of measure (dimensions’ scores). The distribution of the dimensions’ scores represented in Figures 1 through 4 was bell-shaped except for the first dimension, for which the score’s distribution followed a bimodal curve. These standardized dimensions provided several advantages compared with the original variables because they:




Table 3 shows the spearman correlation coefficient between the four SC dimensions and the original variables. The dimensions, represented as linear, quintile and standard deviation scores, were strongly correlated with the original variables, confirming the goodness of the NLPCA in creating new dimensions, which were optimally scaled measures of the original variables.


LR models were carried out to compare the power of the dimensions vs. that of the original variables in predicting intermediate outcomes. Each ‘intermediate outcome’ was recoded into a binomial variable to provide the dichotomous dependent needed for each LR model. For each outcome entered as dependent variable there were two models, in the first model the dimensions were entered as independent variables and in the second model the original SC variables were entered as independent variables. The Rsquares of the two models are in Table 4, where each column shows the outcome variable used as dependent, the Rsquare of the first model containing the SC dimensions and the Rsquare of the second model containing the original variables of SC as independent variables against the outcome variable as dependent. For each outcome, the proportion of variance explained by the SC dimensions was very similar to that explained by the original SC variables, suggesting that the SC dimensions were as good predictors of ‘intermediate outcomes’ as the original variables defining SC.

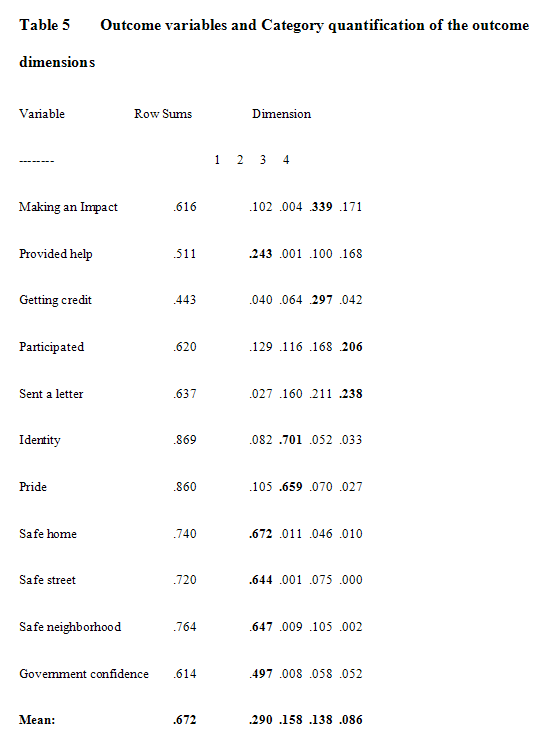
The NLPCA and the Cluster Analysis (CA) were applied to the intermediate outcome variables to cluster the households into two groups with different overall intermediate outcome. The NLPCA was applied this time on the intermediate outcome variables to create household intermediate outcome dimensions. The CA was applied to these dimensions to partition the households into a better off and a worst off group in terms of intermediate outcome. The first four dimensions of the NLPCA model (table 5) explained 67% of the intermediate outcome variance, showing that the information of the original variables was well summarized by the four intermediate outcome dimensions. The first dimension explained 29% of the variance and was characterized by variables related to security. The other three dimensions explained more than 40% of the variance and were characterized by variables related to identity and pride (dimension 2), feeling of making an impact on the community confidence in obtaining credit (dimension 3) and political engagement (dimension 4).

The CA was applied on the households’ intermediate outcome dimensions to divide the households into two clusters having similar intermediate outcome. Fig 1 gives a graphic representation of the two clusters of households in the tri-dimensional space provided by the first three outcome dimensions.

Once the NLPCA and the CA were used on the original variables to divide the sample into two clusters with different levels of intermediate outcome, a LR model was carried out to measure the power of the SC dimensions to predict the probability of belonging to the best cluster. Table 7 shows the LR model in which the SC dimensions (independent variables) were used to predict the chance of belonging to the best cluster (dependent). The model explained about 16% of the variance and showed that the dimensions were significant predictors of belonging to the better off group, confirming the positive association of the SC dimensions with intermediate outcome. The odds of belonging to the best cluster increased by 1.4, 1.9 and 1.5 respectively for each unit increase of the first, second and fourth dimension (Table 7).

The analysis has helped to improve the definition and measurement of SC and its intermediate outcomes, and to measure their relationships at the micro level. The series of surveys on SC promoted by the World Bank has the objective to create a set of empirical tools to improve the measurement of SC. This analysis, which was conducted on the data collected in one of these surveys, was successful in capturing most of the information of the original variables of SC into a few comparable dimensions, which had a standardized metric. The first dimension was characterized by variables related to networking, the second one was a proxy of social interaction and trust, the third one was associated with behavioral norms and the fourth one was characterized by the reliance on the neighborhood in case of need. The SC dimensions were strongly correlated with the original variables and were as good as the original variables in predicting outcomes. The use of the NLPCA and CA allowed to produce a composite measure of intermediate outcome and to measure its association with the SC dimensions.
The advantage of using the dimensions compared with the original variables lies in the easier interpretation of the association between predictors (independents) and intermediate outcome (dependent). For example the first column on table 4 suggests that the probability of thinking to be able to make an impact on the community increased with each SC dimensions’ decile. This is more efficient than using the original SC variables to state that the respondent would have been more likely to think to be able to make an impact on the community if he/she:
The results of this study confirm that the measurement of SC can be improved but that the SC of a whole country is unlikely to be represented by a unique metric. The approach used in this study, which has focused on the micro level, could be expanded to the meso and macro level, to improve the understanding on how the different levels interact to produce SC. Such metric should help to improve the comparison of SC across surveys and should facilitate the testing of hypotheses on the determinants and effects of SC; on the links between the micro, meso and macro level; and on the relationship between household level of SC and final economic and health outcomes. This would provide a more comprehensive picture of the different aspects of SC at various levels and it would help to build hypotheses on how the different levels interact through the production of intermediate outcomes. This leads to the conclusion that it is unlikely that the SC of a country could be reduced to a number because even if a more standardized metric were built it should be specific to the micro, meso and macro level and to its intermediate outcomes.
Andemberg,M. R. 1973. Cluster Analysis for applications, New York: Academic Press.
Brehm, J. and Rahn, W. 1997 ‘Individual-Level Evidence for the Causes and Consequences of Social Capital’, American Journal of Political Science 41(3): 999-1023.
Fassin, D. 2003 ‘Le capitalsocial, de la sociologie a l’epidemiologie: analyse critique d’une migration transdisciplinaire’, Revue d’Epidemiologie et de Sante’ Publique 51: 403-413.
Grootaert, C. 1999 Social Capital, Household Welfare, and Poverty in Indonesia. Policy Research Working Paper No. 2148. The World Bank Social Development Department.
Grootaert, C., Narayan, D., Jones, V.N. and Woodloock, M. Measurng Social Capital. An Integrated Questionnaire. World Bank Working Paper No. 18. The World Bank, November 2003.
Kramer, MA. 1991 ‘Nonlinear principal component analysis using autoassociative neural networksrsquo; American Institute of Chemical Engineers Journal 37: 223-243.
Krishna, A. and Uphoff, N. 1999 Mapping and Measuring Social Capital: A Conceptual and Empirical Study of Collective Action for Conserving and Developing Watersheds in Rajasthan, India. Social Capital Initiative Working Paper No. 13. The World Bank. Washington, D.C.
Narayan, D. and Pritchett, L. 1997 Cents and sociability. World Bank Policy Research Working Paper No. 1796. World Bank . Washington, D.C.
Portes A. 1998 ‘Social Capital its Origins and Application in Contemporary Sociology’, Annual Review of Sociology. 24: 1-24.
Puttnam R.D. 1993 Making democracy work. Civic traditions in modern Italy, Princeton, N.J.: Princeton University Press.
Whiteley, P.F. 2000 ‘Economic Growth and Social Capital’, Political Studies 48 (3): 443-466.
© Electronic Journal of Sociology