| |
|||||||||||||||||
|
|
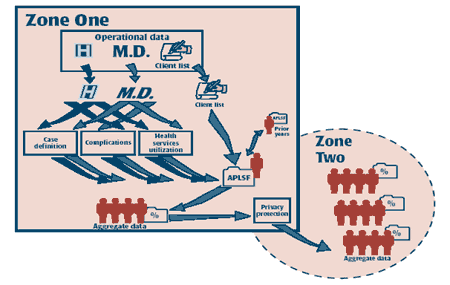
A model for non-communicable disease surveillance in Canada: The Prairie Pilot Diabetes Surveillance System Abstract The Prairie Pilot Diabetes Surveillance Project was organized to design and test a prototype population-based surveillance system, using administrative data, for a chronic disease exemplar - diabetes mellitus. The Canadian model of a public health surveillance system for chronic conditions described here specifies a process by which administrative and claims data arising from provincial health insurance programs are merged into an annual person-level summary file (APLSF), yielding one summary record for each person insured within each province. The APLSF is the basis for a variety of estimates, including incidence, prevalence, mortality, complication rates and health services utilization. The model was used to produce comparable interprovincial estimates of several parameters with respect to diabetes for the entire population in the provinces of Alberta, Manitoba and Saskatchewan. All processing of identifiable health data occurred within the provinces where the data were generated. Combining results across provinces was based on further aggregation of the summary data from each province and not by pooling of identifiable person-level data. On the basis of preliminary outputs for diabetes mellitus, the model appears to provide coherent estimates of key diabetes parameters and reflects anticipated differences in health services and outcomes, by disease state. Three characteristics of the model recommend it as a resource for non-communicable disease surveillance in Canada: a) it maximizes the utility of existing data; b) it includes both those with and those without the disease in question; and c) it respects provincial legislation regarding personal health data, yet permits reporting of multi-provincial, population-based data. Key words: administrative data; chronic diseases; diabetes mellitus; non-communicable disease; population-based data, public health surveillance Introduction Population-based estimates of health and disease are key outputs of public health surveillance activities.1 What are often unavailable for important chronic conditions, however, are reliable estimates of comorbidities, premature mortality, and both direct and indirect costs; measures of incidence, prevalence, duration and remission; and case-fatality rates.2 This deficiency reflects a paucity of models for population-based surveillance of chronic diseases. Secondary analysis of population-based data arising from provincial health insurance programs has been proposed as a way of addressing this problem.3 This is particularly attractive in Canada because of the population perspective provided by provincial and territorial health insurance systems: except for specific exclusions from provincial health plans, such as members of the military and federal police officers, all residents of Canada are insured for health services. Each province or territory organizes its own system of insurance, and each generates some form of unique personal identifier that is used to confirm eligibility for insurance. This identifier is used across ambulatory care and hospital data collection systems. Several investigators have used administrative data in studies of specific chronic diseases.4-10 The Manitoba diabetes surveillance system, with academic and governmental participation, has furnished estimates of incidence, prevalence and complication rates as well as projections of the future burden of diabetes.4,5,11,12 Various Canadian research institutions have offered epidemiologic estimates for a variety of conditions from existing administrative databases, but these projects are typically episodic in nature and research-oriented, and thus do not replace the need for population-based, longitudinal public health surveillance. Moreover, these research projects have not typically been components of multiprovincial or national public health surveillance activities. Unrealized opportunities exist for sustained, multiprovincial and national public health surveillance initiatives using administrative data. The Prairie Pilot Diabetes Surveillance Group was organized to design and test a population-based and interprovincially replicable approach to surveillance for one chronic condition, diabetes mellitus, based on administrative data. Initially, the group intended to transfer the existing diabetes surveillance system from Manitoba to Saskatchewan and Alberta, thereby facilitating the reporting of multiprovincial data,4,5 but the work evolved to include a significant broadening of the "Manitoba model". This article reports on the revised model, its attributes and limitations, and presents some of the results of analyses of multiprovincial, population-based diabetes data. The model Two distinct zones characterize this surveillance system (Figure 1). Zone One (indicated by the square) is distinguished by the availability of population-based, person-level information, typically acquired through the administration of publicly funded health care services. In Canada, provinces and territories typically hold these data. A limited set of agencies within the federal government are also custodians of personal health data for select populations, including federal prisoners, and members of the military and the national police force. While all these agencies could be members of Zone One, our experience and this article is limited to provinces and territories. Zone Two (indicated by a circle) reflects audiences for surveillance data who do not have access to person-level information; in Canada, Zone Two would include the public, many health-related advocacy groups, the evaluation and planning units of provincial health ministries, and the federal government in its national health policy and planning role. It is important to note that different agencies within a political jurisdiction (such as a province) may be allocated to different zones according to their need to hold individual-level health data. FIGURE 1
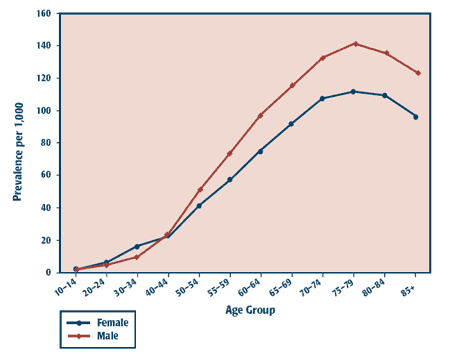
Within Zone One, the model proceeds through a series of steps to manipulate person-specific transaction data. During this process, the unit of observation evolves from inputs that are person-specific and transaction-based to generate summarized information about individuals; these person-level summaries are then further aggregated to generate information about populations. In the model, only aggregated data are transferred from Zone One to Zone Two. This reflects the notion that Zone Two entities do not require person-level health data for their activities. Aggregate datasets are intended to include appropriately stratified counts, rates, sums and other distributional statistics for epidemiologic parameters - for example, incidence and prevalence rates - relevant to the condition under study. We will now discuss each Zone and the constituent steps in more detail. Zone One Within Zone One, four key processes occur: raw data are acquired, the data are manipulated, the key data product - the Annual Person-Level Summary File (APLSF) - is constructed, and various aggregate datasets are generated from the APLSF. Each of these four processes merits detailed discussion. Data inputs: The model requires that key operational databases supporting health insurance systems within a jurisdiction can be copied and made available for surveillance purposes. At least three key files must exist: a comprehensive list of insured persons (the client list), together with listings of medical/ambulatory care (denoted "M") and hospital services ("H") provided to those individuals. Critical characteristics of these files include a unique person-specific identifier to enable data linkage across files, a list of insured persons that provides a reliable census of those eligible for insurance coverage, and information on age, sex, location, periods of insurance and, for those who are deceased, the date of death. Finally, the ambulatory care and hospital discharge databases must contain diagnostic information. (These conditions are satisfied in many, but not all Canadian provinces/territories; recent developments toward a national electronic health record should encourage national compliance.) Data manipulation: Once the data have been acquired, the second step involves sorting and linking inputs by personal identifier, and manipulating and summarizing these inputs to provide annual summary information that will support three distinct activities: 1) case identification, 2) measurement of health services utilization, and 3) detection of complications or comorbidities. These three activities applied over the two service-related inputs create a total of six processes, each with its own distinct logic and outputs. Details regarding how these six data manipulation processes work, including the specification of case definitions and what complications and health services are captured, are not defined by the model itself and need to be developed and validated with each new disease surveillance activity. Creation of an annual person-level summary file: The outputs from the six processes described are combined with information abstracted from the client list (which typically includes age, sex and the vital status of the individual) and prior years of the summary file to produce an APLSF. (Very occasionally, transaction events cannot be linked back to an individual identified in the client list; these transactions are discarded, and the number of discarded transactions is recorded.) The APLSF file contains one record per person per year for each and every person who was insured within a participating jurisdiction at any point in the year, regardless of whether health services were used in that year. The unit of observation in this file is the individual. Each record in the APLSF would typically include annual counts and sums for selected health services utilization for that individual, dates indicating when selected events, diagnoses or complications occurred within the year, and demographic information. Aggregation and rate estimation: The APLSF constitutes the basis for producing various aggregate datasets, which would typically include rates, counts and distributional characterizations for population groups stratified by age, sex, geographic region and imputed disease state. Because the APLSF includes a record for every person within a jurisdiction, it provides estimates of the population at risk for specific outcomes. A variety of possible denominators can be estimated from the APLSF, including mid-year population estimates and person-years-of-observation estimates. External sources of denominator information such as census-based population counts might be preferred in some jurisdictions. Jurisdictions with client lists that do not accurately reflect the population structure may wish to consider census data or other denominator data sources. Among the types of aggregate estimates that would typically be generated from the APLSF datasets are rate estimates for incidence, prevalence and mortality, together with distributional characterizations of physician fees and days in hospital. Again, these parameters can be stratified by geographic and demographic characteristics, and imputed disease state. Zone Two Zone Two is intended to provide a context for the transfer of aggregated data for audiences who are not custodians of person-specific data. Transferring Data Under this model, aggregate datasets being prepared for distribution from Zone One to Zone Two would be checked for residual disclosure risks within Zone One, and only then released into Zone Two. Appropriate stratifications of key demographic variables such as age or geographic region can be defined on an ad hoc basis, depending on the variables available from the client list, in such a way as to provide maximum flexibility in reporting results while ensuring the protection of personal privacy. Additional considerations may include consistency of reporting across Zone One agencies. A wide variety of options exist to ensure the confidentiality of aggregated datasets, including the long-established standard of suppressing cells with small numbers, and several newer methods.13 Implementation issues The model was implemented with the use of SAS® (registered trademark of SAS Institute Inc.). It consisted of a large body of software that was common across the three Zone One participants - the prairie provinces of Alberta, Manitoba and Saskatchewan. A small body of code was also created, specific to each jurisdiction, that supported the use of a common data dictionary across the three jurisdictions (each of which have distinct information technology solutions and data dictionaries) and managed various local details such as filenames and the number of years of input data. (Details on the software are available from the authors on request.) A common body of software across jurisdictions simplified development and deployment, and enhanced comparability. All processing of identifiable health data occurred within the provinces where the data had been generated. Combining results across provinces was based on further aggregation of the already summarized files produced within each province, not by the pooling of person-level data across provinces. Neither transaction data nor APLSF records were transferred out of their "home" provinces. Only a small subset of the six input/process pathways envisioned by the model was included in the pilot project. For instance, no assessment of complications or comorbidities was undertaken using diagnostic information found in the medical/ ambulatory data. The model, as implemented, was sufficient to replicate the initial Manitoba surveillance model.4,5 An example Methods Software built to implement the model was provided to the provincial health departments of Alberta, Manitoba and Saskatchewan. The software used a slight variant of the Manitoba case definition for diabetes: adults were held to have diabetes if there was ever a single diagnosis of diabetes in a hospital discharge record or two or more diagnoses of diabetes within medical/ambulatory care data during a two-year period. Blanchard et al.4 initially advanced this case definition; subsequent studies by Hux and colleagues estimate that it has a 97% specificity and a 86% sensitivity.14 The denominator for reported rates is derived from estimated person-years of observation - a measure available from the APLSF file. We report data for the most recent year available to this pilot project (1997 or 1998, depending on the province). Because of the pilot nature of the project, estimates should be considered as illustrative of the outputs generated by the model; substantive findings may be subject to further refinement. Results and discussion Figure 2 depicts estimated prevalence rates for diabetes, by sex, combined across the three provinces. The prevalence rate increases smoothly among both males and females until age 75 to 79 years, after which it shows a modest decline. The prevalence rate among females is slightly higher in the 20 to 40 age group, but this is likely an artifact of how gestational diabetes was handled within the pilot. Thereafter, the prevalence rates are higher among males than females. FIGURE 2
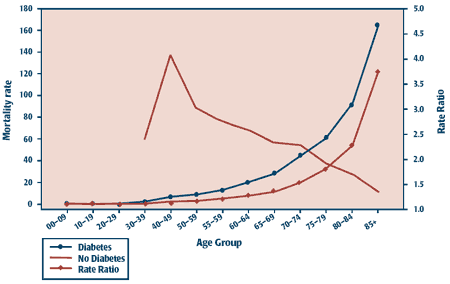
Figure 3 presents the annual mortality rates for diabetic and non-diabetic populations across the prairies and shows an increase with increasing age in both groups. The mortality rate among those with diabetes is consistently higher than among those without diabetes. A rate ratio can be estimated as the quotient of age- and sex-specific mortality rates in the diabetic population and the same rates in the population without diabetes. Before age 70 years, the rate ratio declines from approximately five in the 40-year age group to approximately two in the 70-year-and-older age groups. The ability to report mortality rates in diabetic and non-diabetic populations and to estimate comparative rate ratios reflects the value of including the entire population in the APLSF and in the aggregate datasets. FIGURE 3
The results of this example correspond to anticipated patterns in the epidemiology of diabetes, including greater prevalence with increasing age and higher mortality rates among those with diabetes as compared with the non-diabetic population. Discussion Chronic disease prevention and management require continuing, comparable, systematic surveillance. In countries that are federations, it is important that surveillance be comparable across provinces or states. While several health research centres have reported epidemiologic estimates for specific conditions from time to time, these reports are not public health surveillance activities and are typically episodic, research-oriented and single-jurisdiction analyses. To date, these efforts have not been adapted to address the technical and policy challenges of ongoing surveillance across jurisdictions. Models that address the technical, policy and jurisdictional challenges of comparable interprovincial chronic disease surveillance have not previously been reported. We have described such a model and report preliminary results from a prototype surveillance system for diabetes mellitus. The model has three salient characteristics that recommend it for public health surveillance of chronic conditions: it maximizes the utility of existing data; it includes both those with and without a disease, thereby allowing population-based determination of differential outcomes and health services utilization; finally, it defines distinct and appropriate roles for custodians of personal health data and for those who are not custodians. In this way, it suggests distinct roles for provinces, territories and the federal government that are consistent with Canadian legislative and constitutional realities. Not only does the model generate a registry of persons with a diagnosis of a disease of interest, but it also moves beyond the standard registry approach to include non-cases and to capture complications, health services and health outcomes. This approach allows for the estimation of etiologic fractions for various outcomes and rate ratios for health services utilization, which can be linked back to the specific conditions of interest. For example, under this model, it should be possible to estimate the proportion of the population burden of a complication, such as lower-limb amputation, which occurs in those with diabetes. Existing case-only registers do not typically include non-cases and thus do not allow for these sorts of analyses. The model has limitations. The quality of diagnostic and other information in hospital and medical/ambulatory files must always be considered. The provincial health insurance registries of insured persons must be relatively complete. Innacurate population estimates from lists of insured persons, or incomplete diagnostic information can lead to erroneous epidemiologic estimates. It should also be recognized that administrative data focus largely on diagnoses, procedures and resource utilization rather than risk factors, behaviour or other relevant clinical parameters. The advent of electronic medical records may redress important gaps in data availability and quality. Primary data collection and representative surveys focused on specific disease cohorts may be useful methods of obtaining covariates that are missing from the administrative data. Summarization of personal health information in annual files represents an additional limitation, in that it obscures the ordering of occurrences within each year. When summarization frustrates specific analyses, access to the non-summarized transaction data should remain an option. At this time, the model does not specify a mechanism by which to transfer person-specific health summaries across Zone One agencies. This may mean that migrants with prevalent conditions may be misclassified as incident cases in their destination jurisdiction under this model. The model would be enhanced (and its estimates made more robust) by a method to transmit summary person-level health information across Zone One agencies, particularly when individuals migrate between provinces or territories. The model can also be criticized for not providing person-specific data to the federal government. While our manipulation of data within Zone One agencies resolves several technical barriers to such transfers, we decided to limit person-specific data to Zone One agencies on the basis of our assessment of the Canadian policy environment. Although nominal data transfers occur among provinces, territories and the federal government, these data concern conditions already scheduled in public health legislation or regulations. We are unaware of nominal data transfers across Zone One agencies or to the federal government that relate to non-scheduled diseases such as diabetes. In our experience, provincial and territorial legislative requirements toward data sharing vary widely, as does the willingness to share identifiable, personal health data. In particular, we recognize that there are important and, as yet, not fully answered policy questions regarding data sharing between Zone One entities and with the federal government. The protection provided under the federal Statistics Act might allow for centralization of data across provinces if an epidemiologic rationale could be identified that would require consolidation of data. Ensuring that cases are not double-counted or misclassified as incident cases when individuals migrate from jurisdiction to jurisdiction may be an important facet of such an argument. Provincial privacy commissioners need to play a central role in this issue. The key attribute of this model is its potential generalizability to conditions other than diabetes. Opportunities clearly exist to test this model on other non-communicable diseases and other episodic conditions, notably injuries. Several other important chronic conditions may also be amenable to this approach. However, using this method to augment the number of conditions under surveillance should be complemented by ongoing validation of case definitions, enhancements to the quality of the input health data, active programs of research around the limitations and strengths of such models, programs of linked primary data collection and careful analysis of the outputs from such models. Taken together, these should provide important opportunities to quantify trends in chronic diseases in Canada. This model does not obviate the need for representative surveys. Indeed, the utility of both survey data and administrative data are enhanced when these methods are integrated. For example, linked survey and administrative data provide opportunities to compare self-report with administrative data. Questions regarding conditions that do not generate specific diagnostic codes will not be answered from diagnostic information, but representative surveys incorporating biological samples would be helpful. Close coordination of administrative data and survey methods are strongly encouraged. This model and the results are a proof of concept, demonstrating that multiprovincial public health surveillance based on administrative data can be achieved without cross-jurisdictional sharing of personal health data. Continued validation of input data and validation of the approach for new conditions will be important. The results suggest, however, that this initiative may be an important early contribution towards a national multidimensional picture of population health status, although these methods alone will not yield the entire portrait. Finally, the methods form a foundation of policy, skills, and technology that can and should be used as the impetus to expand public health surveillance capacity across the country. Acknowledgement The authors thank Sylvia Bolt and Dr. Manya Sadouski for their assistance. This work was supported by a financial contribution from the Health Infostructure Support Program, Health Canada, and Alberta Health and Wellness. References
Author References Robert C James, Centre for Health and Policy Studies, Department of Community Health Sciences, University of Calgary, Calgary, Alberta, Canada James F Blanchard, Department of Community Health Sciences, University of Manitoba, Winnipeg, Manitoba, Canada Dawn EJ Campbell, Consultant, Winnipeg, Manitoba, Canada Clarence Clottey, Centre for Chronic Disease Prevention and Control, Health Canada, Ottawa, Ontario, Canada William Osei, Epidemiology, Research and Evaluation Unit, Saskatchewan Health, Regina, Saskatchewan, Canada Lawrence W Svenson, Health Surveillance, Alberta Health & Wellness, Department of Community Health Sciences, University of Calgary, Calgary, Alberta, Canada Correspondence: Tom Noseworthy, Centre for Health and Policy Studies, Health Sciences Building, University of Calgary, 3330 Hospital Drive NW, Calgary, AB Canada T2N 4N1; Fax: (403) 210-3818; E-mail: tnosewor@ucalgary.ca [Previous] [Table of Contents] [Next]
|
|
| Last Updated: 2004-01-09 | |||