| |
|||||||||||||||||
|
|
Short Report
Abstract A two-state deterministic model is used to estimate the incidence of
an irreversible disease from prevalence and mortality data. The method
is simpler than those described previously. Diabetes and dementia are
used as examples.
Introduction This paper deals with diseases that are non-communicable and irreversible. Most so-called "chronic diseases" are of this type. Even where treatment is available to reduce case fatality, such diseases are never cured. The age-specific prevalence of a disease can be measured in population surveys, either by interview or by examination, and the mortality of people with the disease can be obtained from following up the survey subjects or from cohort studies. In the absence of a population-based disease registry, age-specific incidence is more difficult to estimate, since new cases are rare. However, in a stationary population with fixed incidence and mortality rates, the prevalence of a disease is a function of incidence and mortality, and if two elements are known the third can, in principle, be derived. Several approaches to the problem have been suggested,1-5 usually involving rather complex probabilistic models. We describe a simpler method, using a deterministic model, and illustrate its use with data on diabetes and dementia.
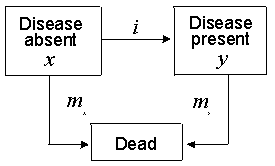
Figure 1 shows a two-state model of disease within a cohort. At a given age, a, x(a) is the number of people without the disease, y(a) is the number of people with the disease, i(a) is the incidence rate, and mx(a) and my(a) are the mortality rates among those without and with the disease. (Note that i is the "true" incidence rate based on those without disease, not on the total population.)
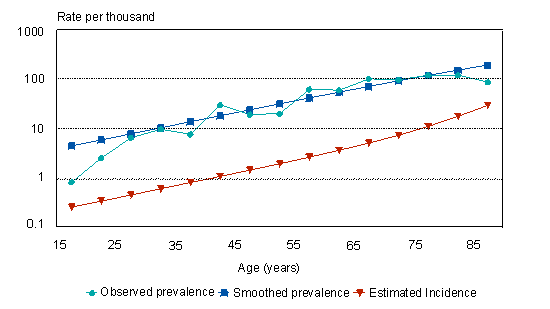
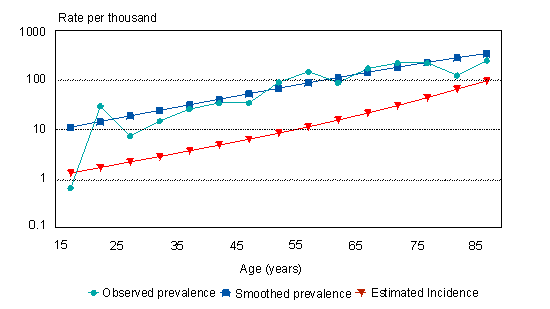
(1) i(a) = pN(a)/{1 - p(a)} + {my(a) - mx(a)}p(a). Also, if my(a)/mx(a) = r, independent of a, and m(a) = the overall mortality rate, then (2) i(a) = pN(a)/{1 - p(a)} + (r - 1)p(a)m(a)/{1 + (r - 1)p(a)}. Since the estimates of age-specific prevalence are usually "noisy," it is necessary to smooth them, taking into account that p(a) must lie between 0 and 1 and, for most diseases, increases monotonically with age. A suitable smoothing function is the logistic ln[p(a)/{1 - p(a)}] = c + b(a). Formula 1 (above) then simplifies to the following formula. (3) i(a) = {b + my(a) - mx(a)}p(a) For diabetes, estimates of p(a) were taken from the 1994/95 National Population Health Survey,6 the 1991 Canadian life table7 was used to estimate m(a), and the estimate of r was taken from US data.8 For dementia, the Canadian Study of Health and Aging (CSHA)9 provided estimates of p(a), and mx(a) and my(a) were derived from a follow-up of the CSHA subjects. The estimates of i(a) using Formula 3 were compared with provisional estimates of incidence from the CSHA (Canadian Study of Health and Aging Working Group, unpublished observations). Results Figures 2 and 3 depict the observed prevalence of diabetes, the smoothed prevalence and the estimated incidence among Canadian women and men. The logistic function fits the observed prevalence reasonably well except at the extremes of the age range. Among women, the estimated incidence increases from 0.3 per 1,000 at ages 15-19 to 29 per 1,000 at ages 85-89. The corresponding estimates among men are 0.2 and 59 per 1,000. |
||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||
|
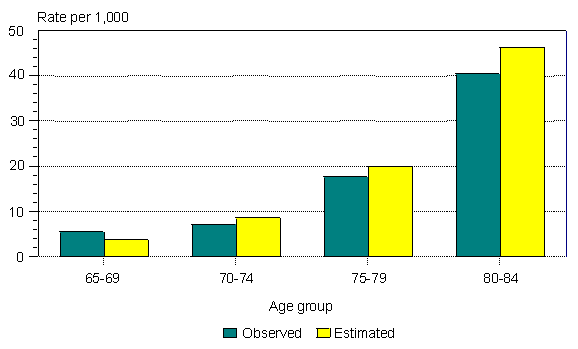
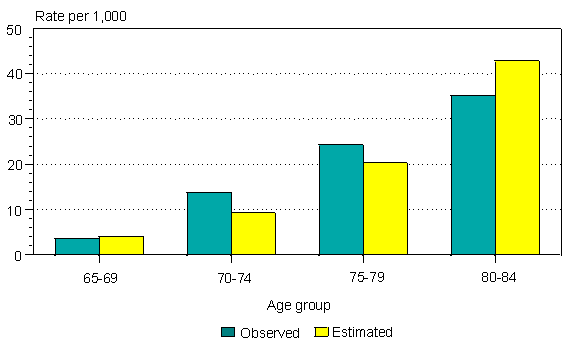
Among elderly Canadian women and men, the observed incidence of dementia from the CSHA follow-up is compared with the incidence estimated from the initial prevalence and subsequent mortality (Figures 4 and 5). The two sets of estimates are similar, but the correspondence is better for women than for men.
|
|||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||
|
Discussion The method involves simple calculations, except for fitting the logistic function to the prevalence data, and programs for doing this are widely available. The use of the logistic is biologically plausible if we postulate, as in bioassays, that disease occurs as a result of a toxic dose that accumulates with age, and the tolerance of an individual (i.e. the lowest dose at which the disease occurs) is normally distributed. Then, conditional on survival, the functional relation between prevalence of disease and age would be that of the normal integral. The logistic is a good approximation to the normal integral and is easier to fit. The incidence estimates for diabetes are consistent with the averages for developed countries,10 but are somewhat lower than estimates for the United States.11 As mentioned, the model applies only to diseases that are irreversible, otherwise x(a) would be replenished from y(a). Thus, the method would be inappropriate for some common chronic diseases (e.g. asthma, migraine, epilepsy) that tend to wane in middle age. Even if the disease is irreversible, it is not necessarily the case that prevalence increases monotonically with age. In fact prevalence will decrease if i(a) < {my(a) - mx(a)}p(a). Thus the prevalence of the disease will decline with age if its incidence does not keep pace with the excess mortality associated with it. Examples would include congenital diseases and also some neurological diseases such as multiple sclerosis. In such circumstances the formulae for the estimation of incidence would still apply, but the use of the logistic function for smoothing would be inappropriate. For some diseases, such as arthritis, and for some disabling conditions, such as deafness and blindness, there is no excess mortality. The formula for incidence then simplifies to i(a) = pN(a)/{1 - p(a)}. At present we have direct estimates of the incidence of cancer derived from provincial cancer registries. In an ideal world we would have registries for all chronic diseases, but this would be very expensive. An alternative approach would be to link hospital discharge records and death records to form an electronic registry for each disease. This is feasible but is difficult to achieve at the national level because of confidentiality restrictions. Longitudinal follow-up of subjects in the National Population Health Survey may provide information on incidence as well as prevalence. In the interim, the approach suggested here may help to fill the gap.
1. Elandt-Johnson RC, Johnson NL. Survival models and data analysis. New York: Wiley, 1980. 2. Leske MC, Ederer F, Podgor M. Estimating incidence from age-specific prevalence in glaucoma. Am J Epidemiol 1981;113:606-13. 3. Podgor MJ, Leske MC. Estimating incidence from age-specific prevalence for irreversible diseases with differential mortality. Stat Med 1986;5:573-8. 4. Newman SC, Bland R. Estimating the morbidity risk of illness from survey data. Am J Epidemiol 1989;129:430-8. 5. Dewey M. Estimating the incidence of dementia in the community from prevalence and mortality results. Int J Epidemiol 1992;21:533-8. 6. Statistics Canada (Health Statistics Division). National Population Health Survey (NPHS): public use microdata files, 1994-95. Ottawa, 1995. 7. Statistics Canada. Life tables, Canada and provinces, 1990-1992. Ottawa, 1995;Cat 84-537-XPB. 8. Kleinman JC, Donahue RP, Harris MI, Finucane FF, Madans JH, Brock DB. Mortality among diabetics in a national sample. Am J Epidemiol 1988;128:389-401. 9. Canadian Study of Health and Aging Working Group. Canadian Study of Health and Aging: study methods and prevalence of dementia. Can Med Assoc J 1994;150:899-913. 10. Murray CJL, Lopez AD. Global health statistics. Boston (MA): Harvard School of Public Health on behalf of the World Health Association and the World Bank, 1996. 11. Wilson PWF, Anderson KM, Kannel WB. Epidemiology of diabetes mellitus in the elderly. Am J Med 1986;80 (Suppl 5A):3-9.
|
|||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||
|
Author References Gerry B Hill, William F Forbes (deceased) and Jean Kozak, Research Department, Sisters of Charity of Ottawa Health Service Inc., Élisabeth-Bruyère Pavilion, 43 Bruyère Street, Ottawa, Ontario K1N 5C8; Fax: (613) 562-6387 This article was presented as a poster at the meeting of the Canadian Society for Epidemiology and Biostatistics in May 1999. |
|||||||||||||||||||||||||||||||||||||||||||||
| Last Updated: 2002-10-11 | |||