| |
|||||||||||||||||
| Article court Résumé On utilise un modèle déterministe à deux états
pour estimer l'incidence d'une maladie irréversible à partir
des données sur la prévalence et la mortalité. La
méthode est plus simple que celles qui ont déjà été
décrites. Le diabète et la démence servent ici d'exemples.
Introduction Cet article porte sur des maladies non transmissibles irréversibles, dont font partie la majorité des maladies dites «chroniques». Même lorsqu'il existe certains traitements permettant d'abaisser la létalité de ces maladies, aucun n'est curatif. On peut établir la prévalence d'une maladie selon l'âge en menant une enquête exhaustive dans une population au moyen d'entrevues ou d'examens, et déterminer la mortalité des sujets atteints en assurant le suivi des sujets de l'enquête ou en faisant des études de cohortes. En l'absence d'un registre des maladies dans l'ensemble de la population, il n'est cependant pas aussi facile d'estimer l'incidence selon l'âge, vu la rareté des nouveaux cas. Mais comme, dans une population stable affichant des taux d'incidence et de mortalité fixes, la prévalence d'une maladie est fonction de ces deux paramètres, on peut en principe, si l'on connaît deux des éléments, déterminer le troisième. Pour ce faire, plusieurs approches ont été proposées1-5, qui font habituellement appel à des modèles probabilistes passablement complexes. Nous décrivons ici une méthode plus simple faisant appel à un modèle déterministe, et nous l'illustrons au moyen de données sur le diabète et la démence.
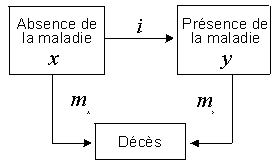
La figure 1 présente un modèle de maladie à deux états au sein d'une cohorte. À un âge donné a, x(a) est le nombre de sujets qui ne souffrent pas de la maladie (les non-malades), y(a), le nombre de sujets qui souffrent de la maladie (les malades), i(a), le taux d'incidence, et mx(a) et my(a), les taux de mortalité chez les sujets malades et non malades. (Noter que i est le taux «réel» d'incidence basé sur les sujets non malades et non sur l'ensemble de la population.)
La prévalence de la maladie à un âge donné est alors p(a) = y(a)/{x(a) + y(a)}. Si pN(a) est la pente de la courbe de la prévalence selon l'âge, on peut alors montrer (voir l'annexe) que (1) i(a) = pN(a)/{1 - p(a)} + {my(a) - mx(a)}p(a). De la même façon, si my(a)/mx(a) = r, indépendamment de a, et m(a) = le taux de mortalité global, alors (2) i(a) = pN(a)/{1 - p(a)} + (r - 1)p(a)m(a)/{1 + (r - 1)p(a)}. Comme les estimations de la prévalence selon l'âge sont habituellement «brouillées par le bruit», il faut les lisser en tenant compte du fait que p(a) doit se situer entre 0 et 1 et que, pour la plupart des maladies, il augmente de façon monotone avec l'âge. Une fonction de lissage qui convient bien ici est la fonction logistique : ln[p(a)/{1 - p(a)}] = c + b(a). La formule 1 (ci-dessus) est alors simplifiée en la formule suivante : (3) i(a) = {b + my(a) - mx(a)}p(a). Pour le diabète, les estimations de p(a) proviennent de l'Enquête nationale sur la santé de la population de 1994-19956, celles de m(a), de la table de survie canadienne de 19917, et celles de r, de données américaines8. Pour la démence, les estimations de p(a) proviennent de l'Étude sur la santé et le vieillissement au Canada (ESVC)9, et celles de mx(a) et my(a) d'un suivi des sujets de l'ESVC. Les estimations de i(a) établies à l'aide de la formule 3 ont été comparées aux estimations provisoires de l'incidence de l'ESVC (Groupe de travail sur l'Étude sur la santé et le vieillissement au Canada, observations inédites).
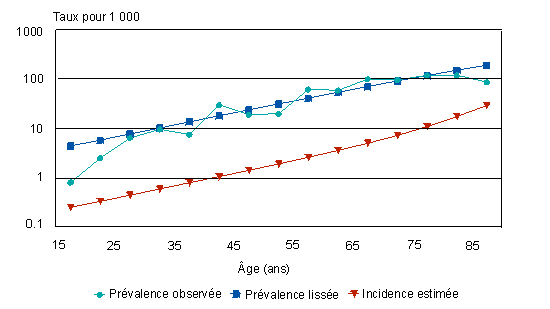
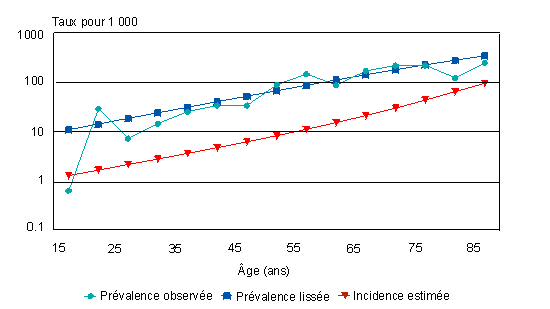
Les figures 2 et 3 illustrent la prévalence observée du diabète, la prévalence lissée et l'incidence estimée chez les Canadiennes et les Canadiens. La fonction logistique ajuste raisonnablement bien la prévalence observée, sauf aux extrêmes de la fourchette d'âges. Chez les femmes, l'incidence estimative augmente de 0,3 pour 1 000, dans le groupe d'âge de 15 à 19 ans, à 29 pour 1 000, dans le groupe des 85 à 89 ans. Chez les hommes, les estimations pour les groupes d'âge correspondants sont de 0,2 et de 59 pour 1 000. |
|||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||
|
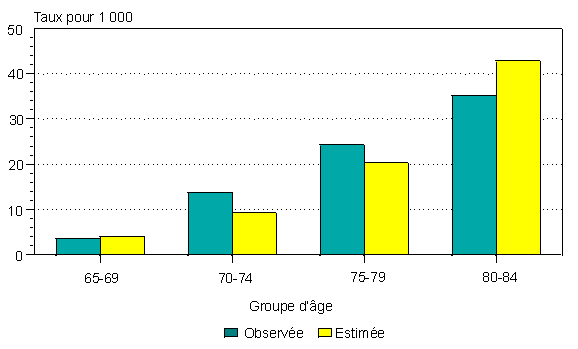
Chez les Canadiennes et les Canadiens âgés, l'incidence observée de la démence établie à partir du suivi de sujets de l'ESVC est comparée à l'incidence estimée à partir de la prévalence initiale et de la mortalité qui s'ensuit (figures 4 et 5). Les deux séries d'estimations sont semblables, mais la correspondance est meilleure pour les femmes que pour les hommes.
|
|||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||
|
Discussion La méthode fait appel à des calculs simples, sauf pour ce qui est de l'ajustement de la fonction logistique aux données de prévalence, pour lesquels il existe des programmes facilement accessibles. Le recours à la logistique est plausible sur le plan biologique si l'on postule, comme dans les dosages biologiques, que la maladie apparaît par suite de l'accumulation d'une dose toxique avec l'âge, et que la tolérance d'un sujet (c.-à-d. la dose la plus faible à laquelle la maladie survient) est normalement distribuée. Alors, selon la survie, la relation fonctionnelle entre la prévalence de la maladie et l'âge devrait être celle de l'intégrale normale. La logistique est une bonne approximation de l'intégrale normale et est plus facile à ajuster. Les estimations de l'incidence du diabète concordent avec les moyennes établies pour les pays industrialisés10, mais sont légèrement plus faibles que les estimations pour les États-Unis11. Tel que mentionné, le modèle ne s'applique qu'aux maladies irréversibles, sinon il pourrait y avoir transfert entre y(a) et x(a). La méthode ne conviendrait donc pas à certaines maladies chroniques courantes (comme l'asthme, la migraine, l'épilepsie), qui s'estompent généralement à l'âge moyen. Même lorsque la maladie est irréversible, la prévalence n'augmente pas nécessairement de façon monotone avec l'âge. En fait, elle diminuera si i(a) < {my(a) - mx(a)}p(a). La prévalence de la maladie diminuera donc avec l'âge si son incidence n'évolue pas de pair avec la surmortalité qui y est associée. On pourrait donner comme exemples les maladies congénitales ainsi que certaines maladies neurologiques, comme la sclérose en plaques. Dans ces cas, les formules pour l'estimation de l'incidence s'appliqueraient toujours, mais il ne conviendrait pas d'utiliser la fonction logistique pour le lissage. Pour certaines maladies, comme l'arthrite, et certaines affections invalidantes, comme la surdité et la cécité, il n'y a aucune surmortalité. La formule de l'incidence se simplifie alors en i(a) = pN(a)/{1 - p(a)}. À l'heure actuelle, nous possédons des estimations directes de l'incidence du cancer, établies d'après les registres provinciaux du cancer. Dans un monde idéal, nous disposerions de registres pour toutes les maladies chroniques, mais cela coûterait fort cher. Une solution de rechange serait de coupler les dossiers de congés des hôpitaux et les dossiers sur la mortalité pour constituer un registre électronique de chaque maladie. Cela est faisable, mais difficile à réaliser à l'échelle nationale à cause des restrictions concernant la confidentialité. Le suivi longitudinal des sujets de l'Enquête nationale sur la santé de la population pourrait fournir de l'information sur l'incidence ainsi que sur la prévalence. Entre-temps, l'approche proposée ici pourrait aider à combler les lacunes.
1. Elandt-Johnson RC, Johnson NL. Survival models and data analysis. New York: Wiley, 1980. 2. Leske MC, Ederer F, Podgor M. Estimating incidence from age-specific prevalence in glaucoma. Am J Epidemiol 1981;113:606-13. 3. Podgor MJ, Leske MC. Estimating incidence from age-specific prevalence for irreversible diseases with differential mortality. Stat Med 1986;5:573-8. 4. Newman SC, Bland R. Estimating the morbidity risk of illness from survey data. Am J Epidemiol 1989;129:430-8. 5. Dewey M. Estimating the incidence of dementia in the community from prevalence and mortality results. Int J Epidemiol 1992;21:533-8. 6. Statistique Canada (Division des statistiques sur la santé). Enquête nationale sur la santé de la population, 1994-1995. Fichiers de microdonnées à grande diffusion. Ottawa, 1995. 7. Statistique Canada. Tables de mortalité, Canada et provinces, 1990-1992. Ottawa, 1995; cat. 84-537-XPB. 8. Kleinman JC, Donahue RP, Harris MI, Finucane FF, Madans JH, Brock DB. Mortality among diabetics in a national sample. Am J Epidemiol 1988;128:389-401. 9. Canadian Study of Health and Aging Working Group. Canadian Study of Health and Aging: study methods and prevalence of dementia. Can Med Assoc J 1994;150:899-913. 10. Murray CJL, Lopez AD. Global health statistics. Boston (MA): Harvard School of Public Health on behalf of the World Health Association and the World Bank, 1996. 11. Wilson PWF, Anderson KM, Kannel WB. Epidemiology of diabetes mellitus in the elderly. Am J Med 1986;80 (Suppl 5A):3-9.
|
|||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||
|
Références des auteurs Gerry B. Hill, William F. Forbes (décédé) et Jean Kozak, Département de recherche, Service de santé des Soeurs de la Charité d'Ottawa inc., Pavillon Élisabeth-Bruyère, 43, rue Bruyère, Ottawa (Ontario) K1N 5C8; Télécopieur : (613) 562-6387 Cet article a été présenté comme une affiche lors de la réunion de la Société canadienne d'épidémiologie et de biostatistiques en mai 1999. |
|||||||||||||||||||||||||||||||||||||||||||||
| Dernière mise à jour : 2002-10-02 | |||